A neural network looks mysterious until you treat it like a careful guesser. It begins with rough beliefs about how inputs link to outputs. As it sees data, it updates those beliefs and tries to speak with confidence only when the evidence supports that stance. This is the heart of a probabilistic viewpoint. It frames training as a repeated update of belief under noise, with clear rules for when a claim should sound bold and when it should sound cautious.
Start with the cast. We have data, a model, parameters, and a scoring rule. In probability language, the scoring rule is the likelihood. It tells us how plausible the observed labels are, given the model’s predictions. If many examples look well explained by the model, the likelihood is high. If the model misses often, it drops. Training searches for parameters that make the observed data look less surprising while keeping the model reasonable rather than twitchy.
Every dataset carries noise. Labels can be imperfect. Measurements can drift. A probabilistic view admits the mess and works with it. In classification, the network outputs a vector of class probabilities. We then treat each label as a draw from that categorical distribution. In regression, we often say the target is a noisy draw around the predicted mean. Under either story, the question is simple. Which parameters make these labels a plausible draw from the model’s distributions?
Common losses connect neatly to that story. Cross-entropy for classification is the negative log likelihood of the correct class. Mean squared error aligns with a Gaussian noise model. When you minimize these losses, you are not chasing an abstract number. You are picking parameters that make the dataset less surprising under a clear generative tale.
Log likelihood translates surprise into an additive scale. Each example contributes a bit of surprise, and those bits add up across the batch. This is convenient for gradients, since sums are easy to differentiate. Stochastic gradient descent then follows the average direction that reduces surprise on small, random slices of data. You can picture a hiker who has a slightly shaky compass that still points roughly downhill most of the time.
Logs also fix a practical issue. Products of many small probabilities underflow. Logs turn products into sums and expose gradients that are smooth and stable. The math matters, but the feeling matters more. Lower loss means the model’s story about how data is generated sounds less far-fetched.
Data is finite, while neural networks can be very flexible. Without guidance, a model may chase quirks that do not repeat. Regularization acts like prior belief about good explanations. Weight decay prefers smaller weights. Dropout discourages reliance on any single path through the network. Early stopping limits the time the model has to memorize noise. From a Bayesian angle, these choices are priors that favor simpler, smoother stories unless the data argues strongly for a complex one.
This lens clarifies trade-offs. Strong priors can prevent wild swings but may miss subtle patterns. Loose priors grant freedom but can track noise. The sweet spot depends on sample size, noise level, and task shape. Thinking in priors turns knob-twiddling into deliberate design.
Fitting yesterday’s data is not the whole job. A trained model should keep its cool on new cases. Validation splits imitate tomorrow by hiding part of today. If validation loss stays low, the network has likely learned patterns that extend beyond the sample. That is only part of the story, though. Confidence should match reality. If the model says 70 percent, it should be right about seven times out of ten.
Calibration methods help here. Temperature scaling adjusts logits after training so predicted probabilities align with observed frequencies. Other approaches, such as isotonic regression, can serve when class boundaries are odd. Good calibration builds trust. It lets users treat a score like a reliable gauge rather than a noisy hunch.
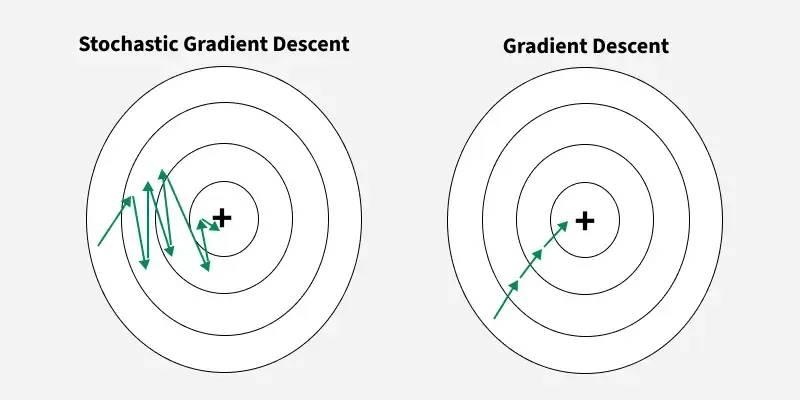
Stochastic gradient descent does not march in a straight line. Mini-batches add noise to the updates, which can keep the model from settling into sharp, brittle minima. Under certain views, this process resembles sampling from a distribution over parameters that fit the data well. You do not need every technical detail to reap value from the idea. The key is that small, random steps help explore many nearly good solutions and favor flatter regions that tend to generalize.
Scheduling matters too. Larger steps early help the network roam across wide basins. Smaller steps later let it settle into a stable area. Momentum carries useful direction across steps, smoothing the path like a flywheel. These choices shape which parameter neighborhoods training prefers, and that preference shows up as different confidence and error profiles at test time.
Standard networks output point estimates. A probabilistic view nudges you to think in distributions. Techniques like Monte Carlo dropout, deep ensembles, and variational layers offer practical paths to predictive uncertainty. With dropout kept on at test time, repeated forward passes act like sampling. Ensembles train several models and combine their predictions. Variational approaches bake uncertainty into the layers themselves. The goal is the same. When the data is ambiguous, the model should admit it and soften its claims.
This mindset pays off in risk-aware settings. A high probability with a narrow spread signals confidence. A middling probability with a widespread warns that the model has not seen enough similar cases. That warning can trigger human review or a default safe action.
A probabilistic viewpoint turns neural network training into a clear narrative. Loss is managed surprise about observed data. Regularization expresses prior belief that steers learning toward stable explanations. SGD, with its noisy steps and schedules, guides the search through broad regions that hold up on new inputs. And predictions can carry honest uncertainty instead of brittle confidence.
This lens does not demand heavy math or grand theory. It asks steady questions. What story about data generation does this loss imply. What beliefs do my regularizers encode. Do my predicted probabilities line up with real outcomes.

Model behavior mirrors human shortcuts and limits. Structure reveals shared constraints.

Algorithms are interchangeable, but dirty data erodes results and trust quickly. It shows why integrity and provenance matter more than volume for reliability.

A technical examination of neural text processing, focusing on information density, context window management, and the friction of human-in-the-loop logic.

AI tools improve organization by automating scheduling, optimizing digital file management, and enhancing productivity through intelligent information retrieval and categorization

How AI enables faster drug discovery by harnessing crowdsourced research to improve pharmaceutical development

Meta’s AI copyright case raises critical questions about generative music, training data, and legal boundaries

What the Meta AI button in WhatsApp does, how it works, and practical ways to remove Meta AI or reduce its presence

How digital tools like Aeneas revolutionize historical research, enabling faster discoveries and deeper insights into the past.

Maximize your AI's potential by harnessing collective intelligence through knowledge capture, driving innovation and business growth.

Learn the LEGB rule in Python to master variable scope, write efficient code, and enhance debugging skills for better programming.

Find out how AI-driven interaction design improves tone, trust, and emotional flow in everyday technology.

Explore the intricate technology behind modern digital experiences and discover how computation shapes the way we connect and innovate.